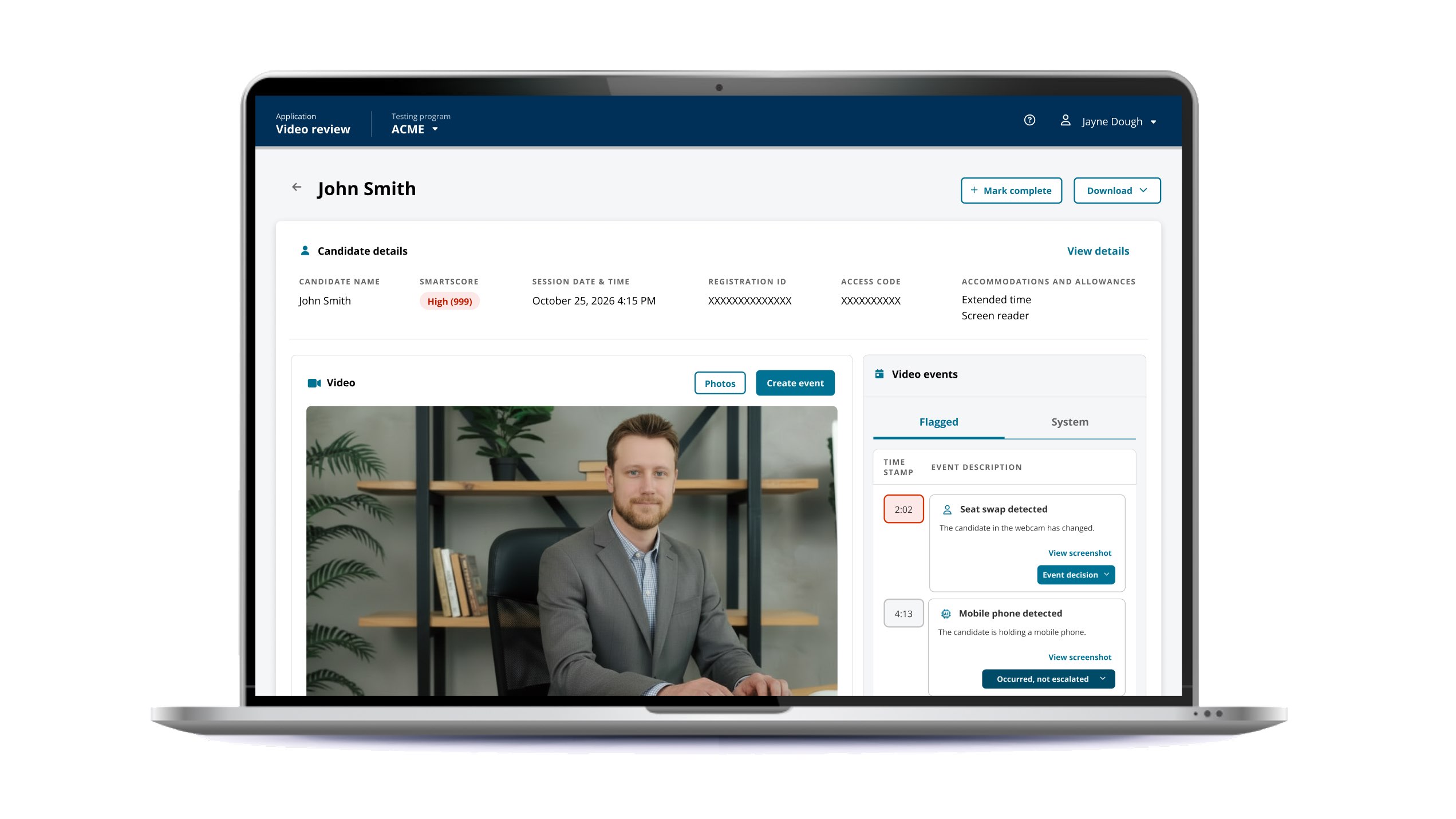
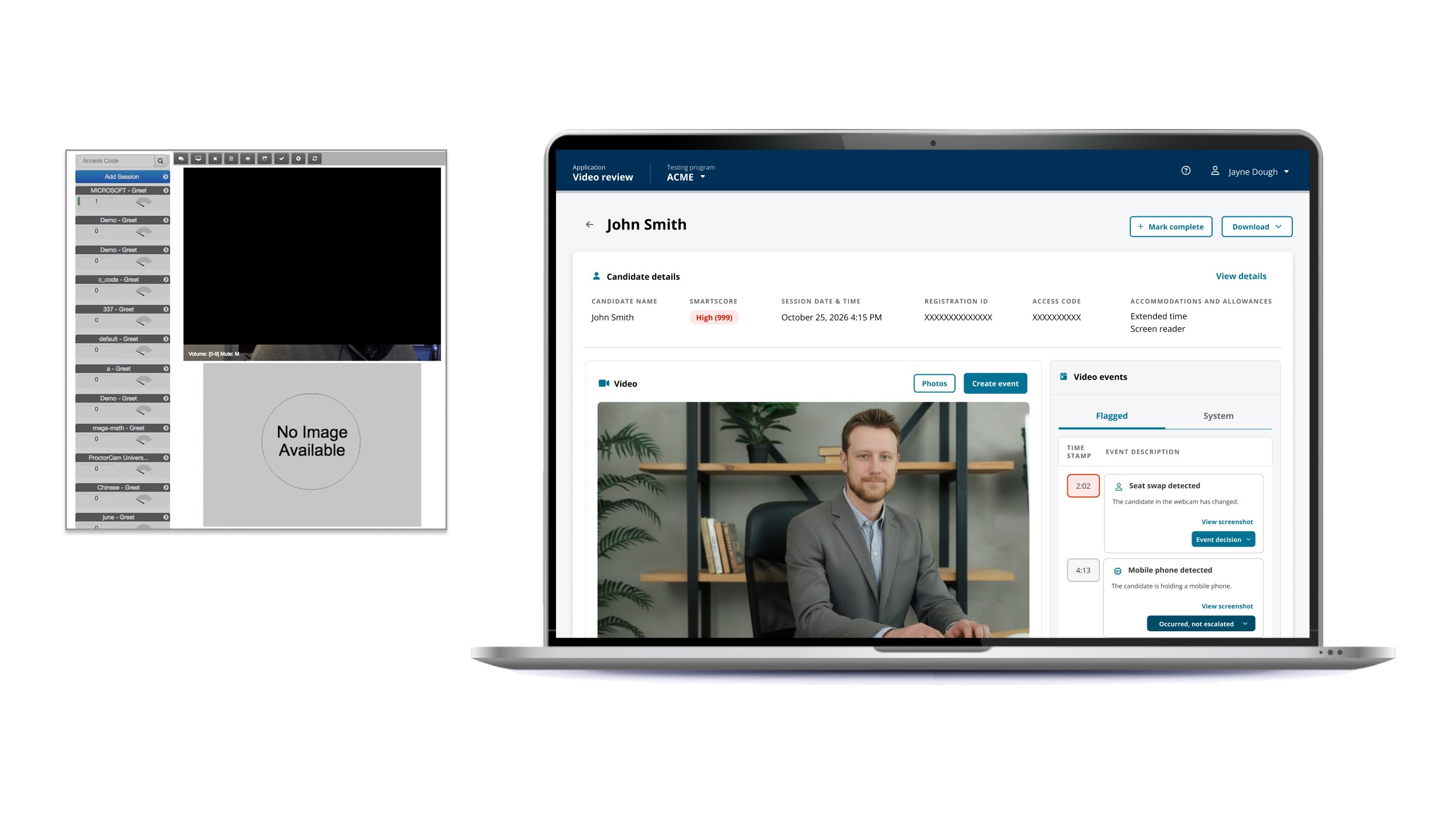
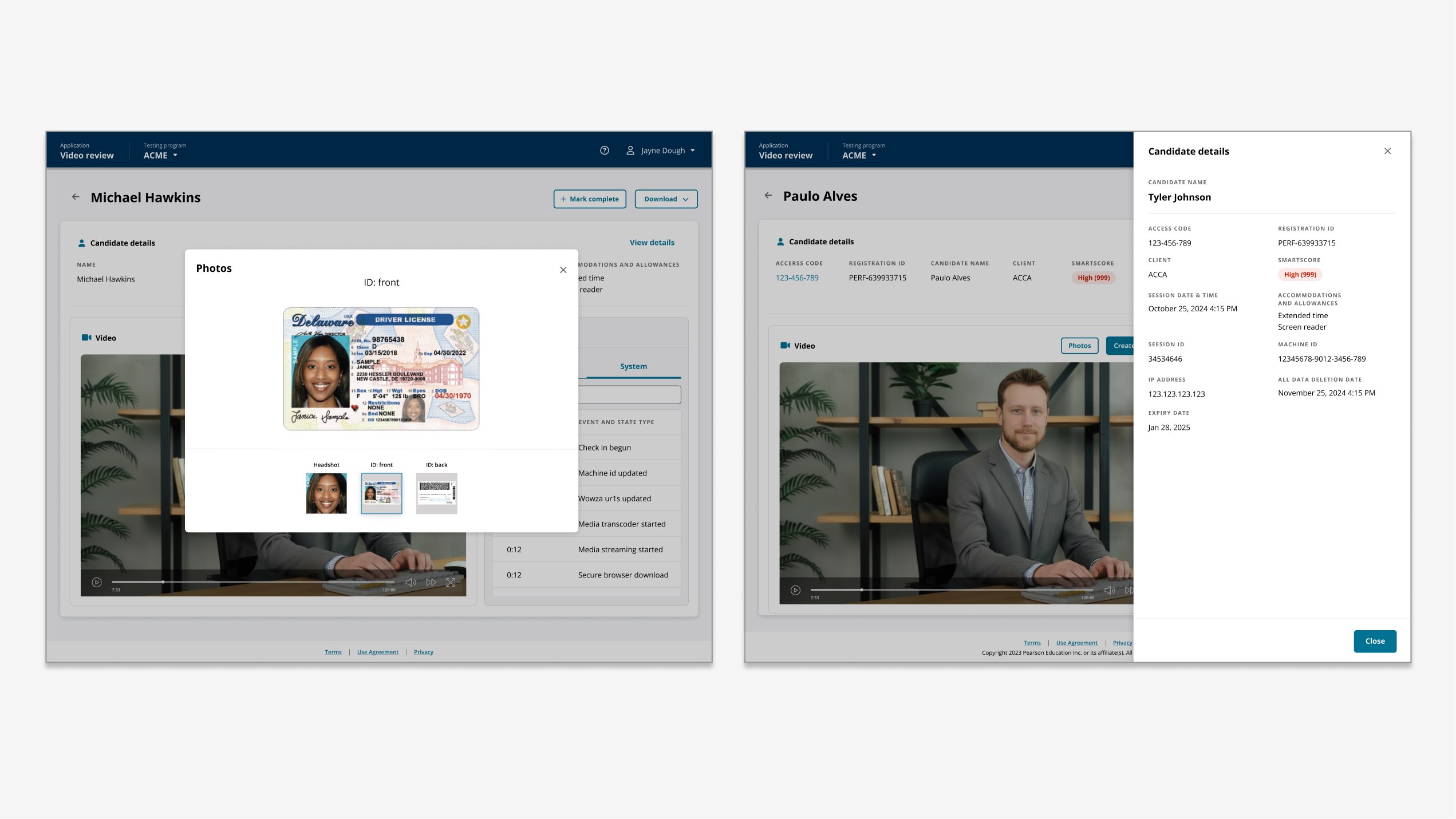
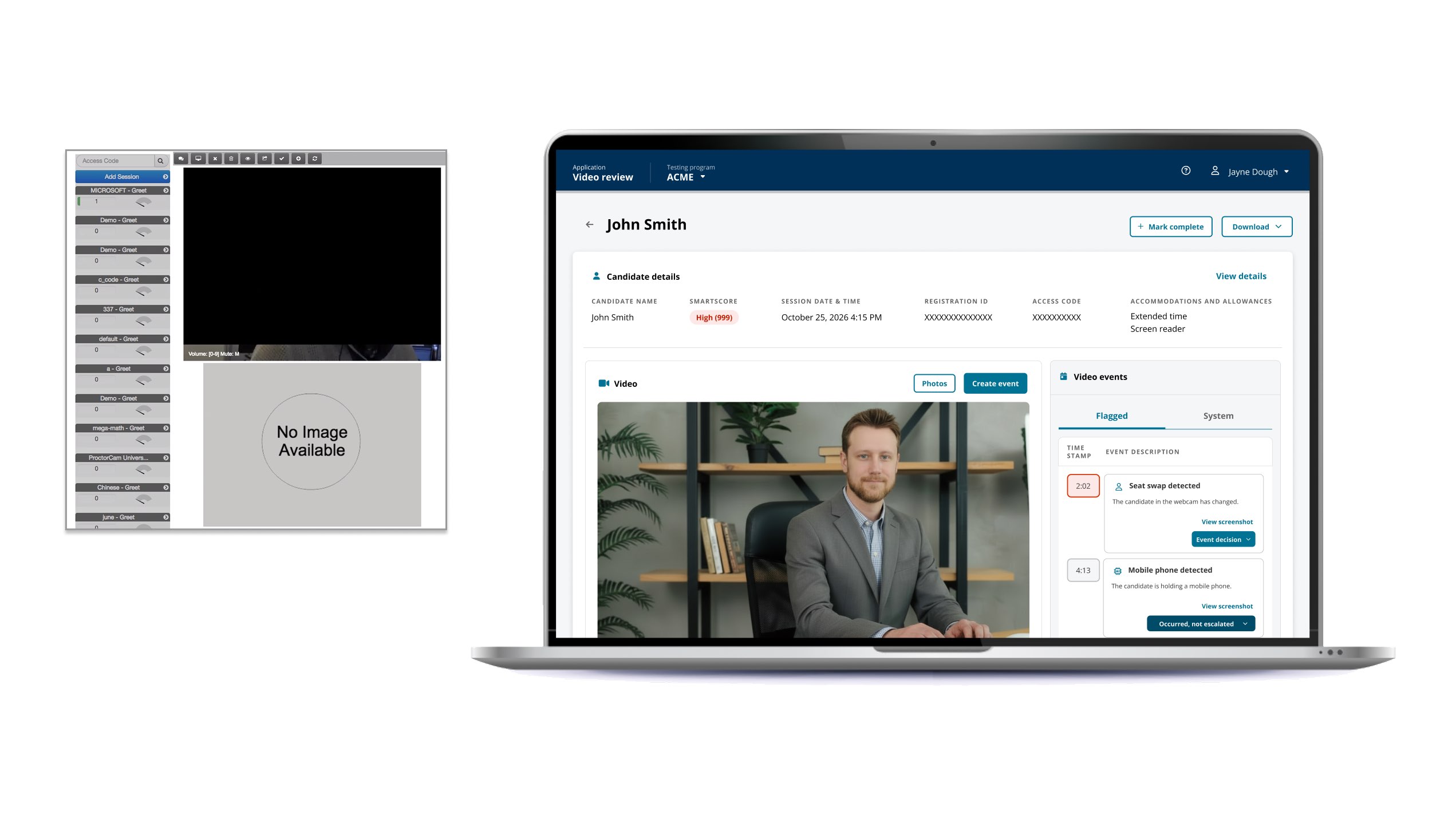
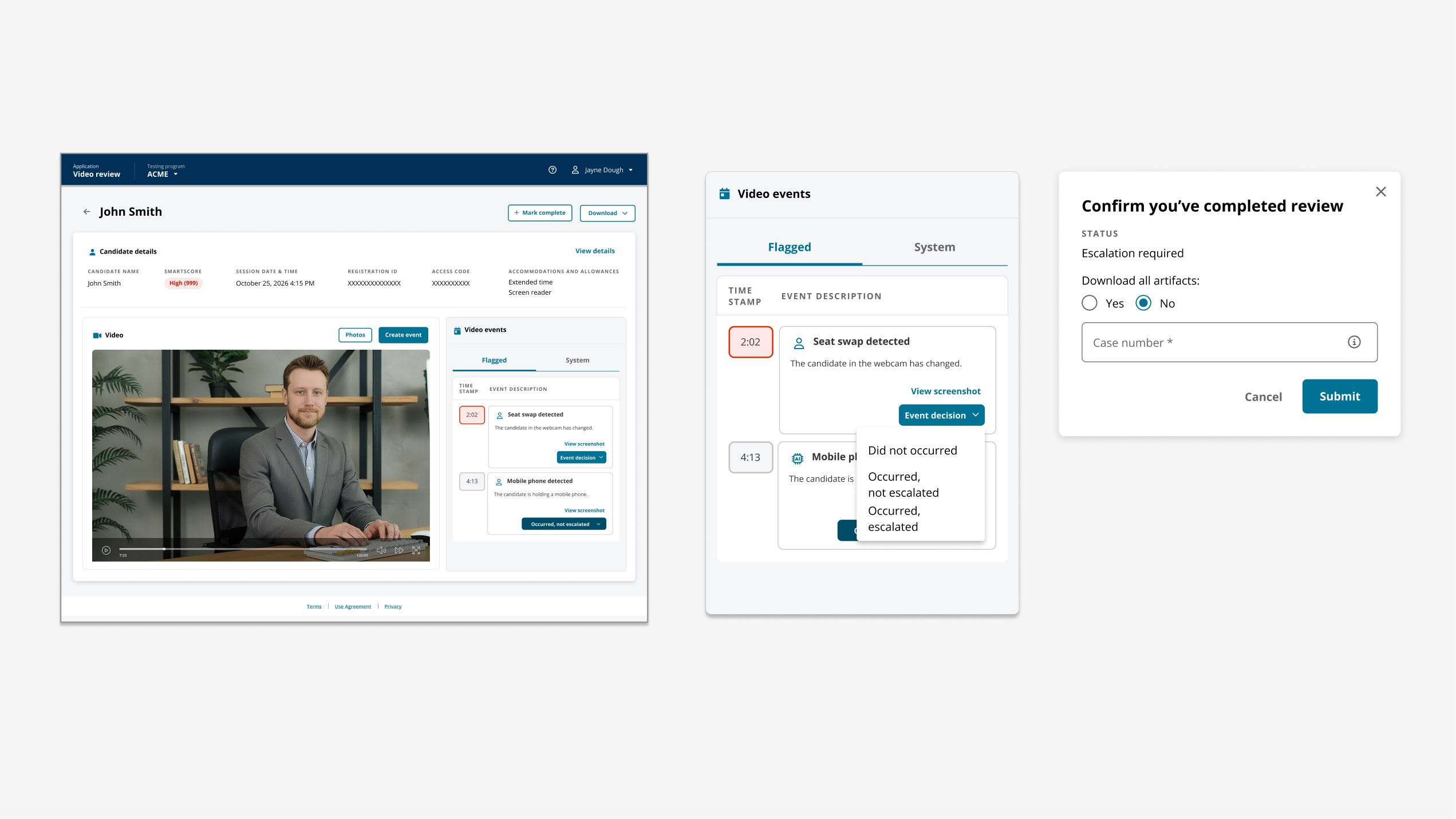
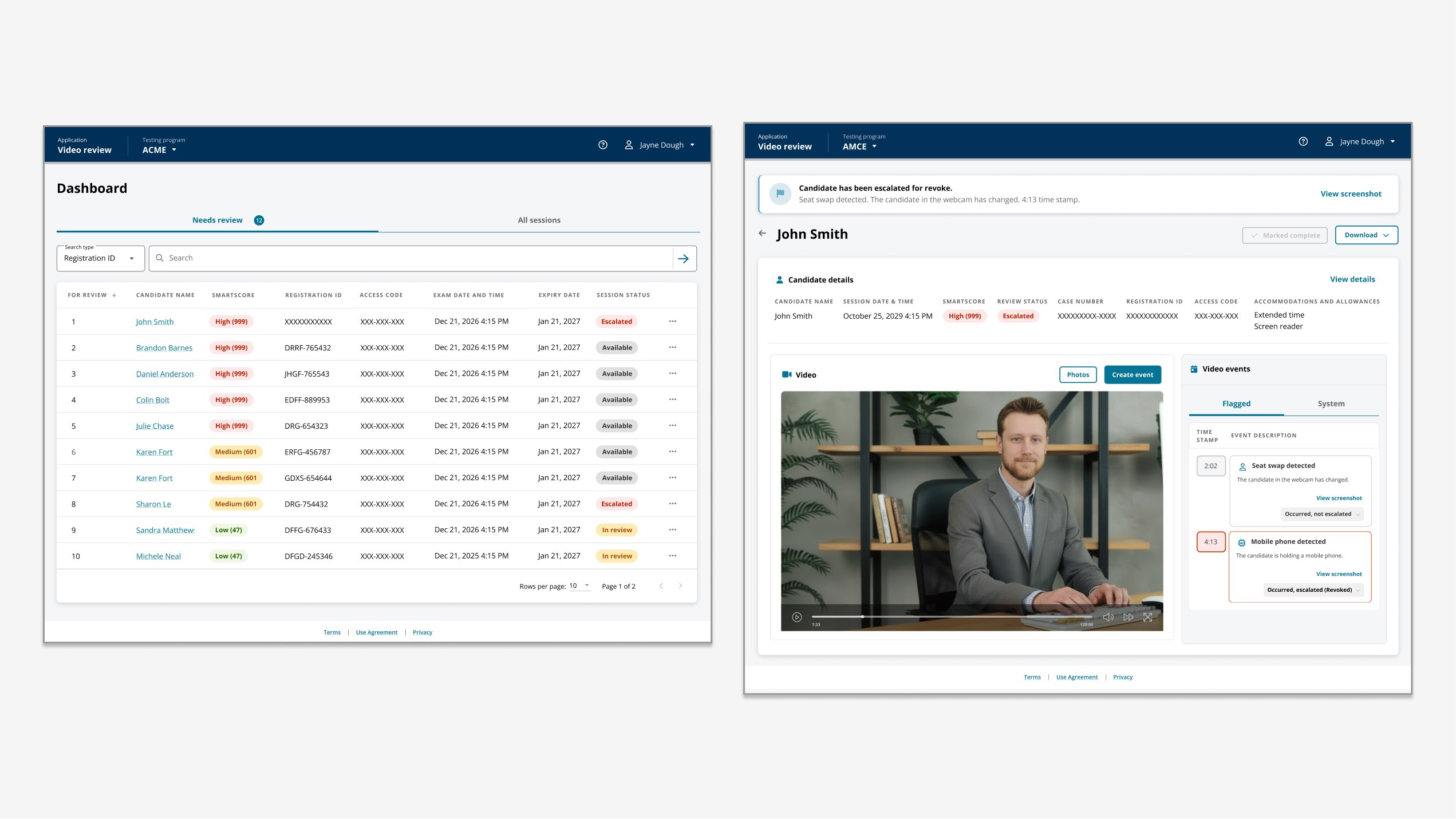
The AI could flag possible exam-integrity events with high recall, but the workflow still required a human to open a case, hunt through dense session video, reconstruct context, and produce a verdict that could survive downstream scrutiny by clients, investigators, and operations.
Raw probability introduced its own risk: without visible supporting evidence, reviewers could over-trust a flag (rubber-stamping), learn to dismiss it (model fatigue), or produce inconsistent decisions (decision drift). The product needed to increase throughput without letting model confidence become the verdict.
The hard tradeoff was security versus operational cost, with each client setting the dial. Clients buying a lower-cost modality still needed real risk coverage. Clients buying live proctoring wanted almost no misconduct slipping through. The same workstation had to support both models through configuration.
What I led: I led the end-to-end design of the dashboard, risk-ranked queue, evidence canvas, event-state model, structured decision paths, audit trail, prototype, validation rounds, and implementation-ready UI. I partnered with Product, Engineering, risk-scoring partners, compliance, and the review operations team that would use the workstation every day.